题文
答案
据专家权威分析,试题“甲、乙两个组各10名同学进行英语口语会话测试,每个人测试5次,每..”主要考查你对 平均数,方差 等考点的理解。关于这些考点的“档案”如下:
平均数方差
考点名称:平均数
平均数、中位数和众数关系:联系: 平均数、中位数和众数都是来刻画数据平均水平的统计量,它们各有特点。对于平均数大家比较熟悉,中位数刻画了一组数据的中等水平,众数刻画了一组数据中出现次数最多的情况。 平均数非常明显的优点之一是,它能够利用所有数据的特征,而且比较好算。另外,在数学上,平均数是使误差平方和达到最小的统计量,也就是说利用平均数代表数据,可以使二次损失最小。因此,平均数在数学中是一个常用的统计量。但是平均数也有不足之处,正是因为它利用了所有数据的信息,平均数容易受极端数据的影响。 例如,在一个单位里,如果经理和副经理工资特别高,就会使得这个单位所有成员工资的平均水平也表现得很高,但事实上,除去经理和副经理之外,剩余所有人的平均工资并不是很高。这时,中位数和众数可能是刻画这个单位所有人员工资平均水平更合理的统计量。 中位数和众数这两个统计量的特点都是能够避免极端数据,但缺点是没有完全利用数据所反映出来的信息。 由于各个统计量有各自的特征,所以需要我们根据实际问题来选择合适的统计量。 当然,出现极端数据不一定用中位数,一般,统计上有一个方法,就要认为这个数据不是来源于这个总体的,因而把这个数据去掉。比如大家熟悉的跳水比赛评分,为什么要去掉一个最高分、一个最低分呢,就认为这两个分不是来源于这个总体,不能代表裁判的鉴赏力。于是去掉以后再求剩下数据的平均数。需要指出的是,我们处理的数据,大部分是对称的数据,数据符合或者近似符合正态分布。这时候,均值(平均数)、中位数和众数是一样的。
区别: 只有在数据分布偏态(不对称)的情况下,才会出现均值、中位数和众数的区别。所以说,如果是正态的话,用哪个统计量都行。如果偏态的情况特别严重的话,可以用中位数。 除了需要刻画平均水平的统计量,统计中还有刻画数据波动情况的统计量。比如,平均数同样是5,它所代表的数据可能是1、3、5、7、9,可能是4、4.5、5、5.5、6。也就是说5所代表的不同组数据的波动情况是不一样的。怎样刻画数据的波动情况呢?很自然的想法就是用最大值减最小值,即求一组数据的极差。数学中还有方差、标准差等许多用来刻画数据特征的统计量。当然这些都是教师感兴趣、值得了解的内容,不是小学数学的教学要求。
考点名称:方差
公式:方差是实际值与期望值之差平方的期望值,而标准差是方差算术平方根。 在实际计算中,我们用以下公式计算方差。方差是各个数据与平均数之差的平方的平均数,即s^2=(1/n)[(x1-x_)^2+(x2-x_)^2+...+(xn-x_)^2],其中,x_表示样本的平均数,n表示样本的数量,^,xn表示个体,而s^2就表示方差。而当用(1/n)[(x1-x_)^2+(x2-x_)^2+...+(xn-x_)^2]作为样本X的方差的估计时,发现其数学期望并不是X的方差,而是X方差的(n-1)/n倍,[1/(n-1)][(x1-x_)^2+(x2-x_)^2+...+(xn-x_)^2]的数学期望才是X的方差,用它作为X的方差的估计具有“无偏性”,所以我们总是用[1/(n-1)]∑(xi-X~)^2来估计X的方差,并且把它叫做“样本方差”。方差,通俗点讲,就是和中心偏离的程度!用来衡量一批数据的波动大小(即这批数据偏离平均数的大小)并把它叫做这组数据的方差。记作S².在样本容量相同的情况下,方差越大,说明数据的波动越大,越不稳定。方差分析主要用途:①均数差别的显著性检验;②分离各有关因素并估计其对总变异的作用;③分析因素间的交互作用;④方差齐性检验。
 =2,
=2, =2,
=2, =1,
=1, =1.8,甲组更稳定.
=1.8,甲组更稳定.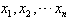 ,那么
,那么  ,叫做这n个数的算术平均数。
,叫做这n个数的算术平均数。  点的权分别为
点的权分别为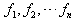 ,那么称
,那么称 为这n个数的加权平均数。
为这n个数的加权平均数。  ;
; 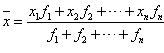 。
。  ,
, ,…,
,…, ,我们用它的平均数,即用
,我们用它的平均数,即用 来衡量这组数据的波动大小,并把它叫做这组数据的方差,记作
来衡量这组数据的波动大小,并把它叫做这组数据的方差,记作 。
。 ,并把它叫做这组数据的标准差,它也是一个用来衡量一组数据的波动大小的重要的量。
,并把它叫做这组数据的标准差,它也是一个用来衡量一组数据的波动大小的重要的量。