题文
答案
据专家权威分析,试题“张老师为了从平时在班级里数学比较优秀的王军、张成两位同学中选..”主要考查你对 平均数,中位数和众数,方差,统计表 等考点的理解。关于这些考点的“档案”如下:
平均数中位数和众数方差统计表
考点名称:平均数
平均数、中位数和众数关系:联系: 平均数、中位数和众数都是来刻画数据平均水平的统计量,它们各有特点。对于平均数大家比较熟悉,中位数刻画了一组数据的中等水平,众数刻画了一组数据中出现次数最多的情况。 平均数非常明显的优点之一是,它能够利用所有数据的特征,而且比较好算。另外,在数学上,平均数是使误差平方和达到最小的统计量,也就是说利用平均数代表数据,可以使二次损失最小。因此,平均数在数学中是一个常用的统计量。但是平均数也有不足之处,正是因为它利用了所有数据的信息,平均数容易受极端数据的影响。 例如,在一个单位里,如果经理和副经理工资特别高,就会使得这个单位所有成员工资的平均水平也表现得很高,但事实上,除去经理和副经理之外,剩余所有人的平均工资并不是很高。这时,中位数和众数可能是刻画这个单位所有人员工资平均水平更合理的统计量。 中位数和众数这两个统计量的特点都是能够避免极端数据,但缺点是没有完全利用数据所反映出来的信息。 由于各个统计量有各自的特征,所以需要我们根据实际问题来选择合适的统计量。 当然,出现极端数据不一定用中位数,一般,统计上有一个方法,就要认为这个数据不是来源于这个总体的,因而把这个数据去掉。比如大家熟悉的跳水比赛评分,为什么要去掉一个最高分、一个最低分呢,就认为这两个分不是来源于这个总体,不能代表裁判的鉴赏力。于是去掉以后再求剩下数据的平均数。需要指出的是,我们处理的数据,大部分是对称的数据,数据符合或者近似符合正态分布。这时候,均值(平均数)、中位数和众数是一样的。
区别: 只有在数据分布偏态(不对称)的情况下,才会出现均值、中位数和众数的区别。所以说,如果是正态的话,用哪个统计量都行。如果偏态的情况特别严重的话,可以用中位数。 除了需要刻画平均水平的统计量,统计中还有刻画数据波动情况的统计量。比如,平均数同样是5,它所代表的数据可能是1、3、5、7、9,可能是4、4.5、5、5.5、6。也就是说5所代表的不同组数据的波动情况是不一样的。怎样刻画数据的波动情况呢?很自然的想法就是用最大值减最小值,即求一组数据的极差。数学中还有方差、标准差等许多用来刻画数据特征的统计量。当然这些都是教师感兴趣、值得了解的内容,不是小学数学的教学要求。
考点名称:中位数和众数
平均数、中位数和众数异同:一、相同点平均数、中位数和众数这三个统计量的相同之处主要表现在:都是来描述数据集中趋势的统计量;都可用来反映数据的一般水平;都可用来作为一组数据的代表。二、不同点它们之间的区别,主要表现在以下方面。1、定义不同平均数:一组数据的总和除以这组数据个数所得到的商叫这组数据的平均数。中位数:将一组数据按大小顺序排列,处在最中间位置的一个数叫做这组数据的中位数 。众数:在一组数据中出现次数最多的数叫做这组数据的众数。2、求法不同平均数:用所有数据相加的总和除以数据的个数,需要计算才得求出。中位数:将数据按照从小到大或从大到小的顺序排列,如果数据个数是奇数,则处于最中间位置的数就是这组数据的中位数;如果数据的个数是偶数,则中间两个数据的平均数是这组数据的中位数。它的求出不需或只需简单的计算。众数:一组数据中出现次数最多的那个数,不必计算就可求出。3、个数不同在一组数据中,平均数和中位数都具有惟一性,但众数有时不具有惟一性。在一组数据中,可能不止一个众数,也可能没有众数。4、呈现不同平均数:是一个“虚拟”的数,是通过计算得到的,它不是数据中的原始数据。中位数:是一个不完全“虚拟”的数。当一组数据有奇数个时,它就是该组数据排序后最中间的那个数据,是这组数据中真实存在的一个数据;但在数据个数为偶数的情况下,中位数是最中间两个数据的平均数,它不一定与这组数据中的某个数据相等,此时的中位数就是一个虚拟的数。众 数:是一组数据中的原数据 ,它是真实存在的。5、代表不同平均数:反映了一组数据的平均大小,常用来一代表数据的总体 “平均水平”。中位数:像一条分界线,将数据分成前半部分和后半部分,因此用来代表一组数据的“中等水平”。众数:反映了出现次数最多的数据,用来代表一组数据的“多数水平”。这三个统计量虽反映有所不同,但都可表示数据的集中趋势,都可作为数据一般水平的代表。6、特点不同平均数:与每一个数据都有关,其中任何数据的变动都会相应引起平均数的变动。主要缺点是易受极端值的影响,这里的极端值是指偏大或偏小数,当出现偏大数时,平均数将会被抬高,当出现偏小数时,平均数会降低。中位数:与数据的排列位置有关,某些数据的变动对它没有影响;它是一组数据中间位置上的代表值,不受数据极端值的影响。众数:与数据出现的次数有关,着眼于对各数据出现的频率的考察,其大小只与这组数据中的部分数据有关,不受极端值的影响,其缺点是具有不惟一性,一组数据中可能会有一个众数,也可能会有多个或没有 。7、作用不同平均数:是统计中最常用的数据代表值,比较可靠和稳定,因为它与每一个数据都有关,反映出来的信息最充分。平均数既可以描述一组数据本身的整体平均情况,也可以用来作为不同组数据比较的一个标准。因此,它在生活中应用最广泛,比如我们经常所说的平均成绩、平均身高、平均体重等。中位数:作为一组数据的代表,可靠性比较差,因为它只利用了部分数据。但当一组数据的个别数据偏大或偏小时,用中位数来描述该组数据的集中趋势就比较合适。众数:作为一组数据的代表,可靠性也比较差,因为它也只利用了部分数据。。在一组数据中,如果个别数据有很大的变动,且某个数据出现的次数最多,此时用该数据(即众数)表示这组数据的“集中趋势”就比较适合。
考点名称:方差
公式:方差是实际值与期望值之差平方的期望值,而标准差是方差算术平方根。 在实际计算中,我们用以下公式计算方差。方差是各个数据与平均数之差的平方的平均数,即s^2=(1/n)[(x1-x_)^2+(x2-x_)^2+...+(xn-x_)^2],其中,x_表示样本的平均数,n表示样本的数量,^,xn表示个体,而s^2就表示方差。而当用(1/n)[(x1-x_)^2+(x2-x_)^2+...+(xn-x_)^2]作为样本X的方差的估计时,发现其数学期望并不是X的方差,而是X方差的(n-1)/n倍,[1/(n-1)][(x1-x_)^2+(x2-x_)^2+...+(xn-x_)^2]的数学期望才是X的方差,用它作为X的方差的估计具有“无偏性”,所以我们总是用[1/(n-1)]∑(xi-X~)^2来估计X的方差,并且把它叫做“样本方差”。方差,通俗点讲,就是和中心偏离的程度!用来衡量一批数据的波动大小(即这批数据偏离平均数的大小)并把它叫做这组数据的方差。记作S².在样本容量相同的情况下,方差越大,说明数据的波动越大,越不稳定。方差分析主要用途:①均数差别的显著性检验;②分离各有关因素并估计其对总变异的作用;③分析因素间的交互作用;④方差齐性检验。
考点名称:统计表
统计表构成及格式:一般由表头、行标题、列标题和数字资料四个主要部分组成,必要时可以在统计表的下方加上表外附加。①表头应放在表的上方,它所说明的是统计表的主要内容。②行标题和列标题通常安排在统计表的第一列和第一行,它所表示的主要是所研究问题的类别名称和指标名称,通常也被称为“类”。③表外附加通常放在统计表的下方,主要包括资料来源、指标的注释、必要的说明等内容。结构:①总标题――概括统计表中全部资料的内容,是表的名称。②横行标题――表示各组的名称,它说明统计表要说明的对象,是横行的名称。③纵栏标题――表示汇总项目即统计指标的名称。④数字资料――是各组、各汇总项目的数值。列在各横行标题与各纵栏标题交叉处,即统计表的右下方。内容构成:主词――是说明总体的,它可以是各个总体单位的名称、总体各个分组名称。行式上表现为横行标题。宾词――是说明总体的指标名称和数值的。形式上表现为纵栏标题和指标数值。
统计表分类:统计表形式繁简不一,通常是按项目的多少,分为单式统计表与复式统计表两种。只对某一个项目数据进行统计的表格,称为单式统计表,也称之为简单统计表。统计项目在2个或2个以上的统计表格,称之为复式统计表。1、按作用不同:统计调查表、汇总表、分析表。2、按分组情况不同:简单表、简单分组表、复合分组表。①简单表:即不经任何分组,仅按时间或单位进行简单排列的表。②简单分组表:即仅按一个标志进行分组的表。③复合分组表:即按两个或两个以上标志进行层叠分组的表。
统计表设计:由于使用者的目的以及统计数据的特点不同,统计表的设计在形式和结构上会有较大差异,但设计的基本要求是一致的。总体上来说,统计表的设计应符合科学、实用、简练、美观的要求。具体来说设计统计表时要注意以下几点:1.合理安排统计表的结构。比如行标题、列标题、数字资料的位置应安排合理。2.表头一般应包括表号、总标题和表中数据的单位等内容。总标题应简明确切地概括出统计表的内容,一般需要表明统计数据的时间、地点以及何种数据,即标题内容应满足3W(统计数据的时间、地点、何种数据的简称)要求。3.如果表中的全部数据都是同一计量单位,可放在表的右上角标明,若各指标的计量单位不同,则应放在每个指标后或单列出一列标明。4.表中的上下两条线一般用粗线,中间的其他线要用细线,这样使人看起来清楚、醒目。5.在使用统计表时,必要时可在表的下方加上注释,特别要注明资料来源,以表示对他人劳动成果的尊重,方便读者查阅使用。
统计表制作规则:1、统计表一般为横长方形,上下两端封闭且为粗线,左右两端开口。 2、统计表栏目多时要编号,一般主词部分按甲、乙、丙;宾词部分按(1)(2)等次序编号。 3、统计表总标题应简明扼要,符合表的内容。 4、主词与宾词位置可互换。各栏排列次序应以时间先后、数量大小、空间位置等自然顺序编排。 5、计量单位一般写在表的右上方或总栏标题下方。 6、表内资料需要说明解释部分,如:注解、资料来源等,写在表的下方。7、填写数字资料不留空格,即在空格处划上斜线。统计表经审核后,制表人和填报单位应签名并盖章,以示负责。
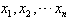 ,那么
,那么  ,叫做这n个数的算术平均数。
,叫做这n个数的算术平均数。  点的权分别为
点的权分别为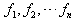 ,那么称
,那么称 为这n个数的加权平均数。
为这n个数的加权平均数。  ;
; 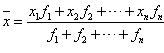 。
。  ,
, ,…,
,…, ,我们用它的平均数,即用
,我们用它的平均数,即用 来衡量这组数据的波动大小,并把它叫做这组数据的方差,记作
来衡量这组数据的波动大小,并把它叫做这组数据的方差,记作 。
。 ,并把它叫做这组数据的标准差,它也是一个用来衡量一组数据的波动大小的重要的量。
,并把它叫做这组数据的标准差,它也是一个用来衡量一组数据的波动大小的重要的量。