在某次体育活动中,统计甲、乙两班学生每分钟跳绳的成绩(单位:次)情况如下表:班级参加人数平均次数中位数方差甲班55135149190乙班55135151110下面有三种说法:(1)甲班学生的平-八年级数学
题文
| 在某次体育活动中,统计甲、乙两班学生每分钟跳绳的成绩(单位:次)情况如下表: | |||||||||||||||
|
答案
解:从表中可以看出,甲班学生平均成绩为135,乙班学生平均成绩也是135,因而甲、乙两班平均成绩相同,所以(1)的说法是错误的;因s =190>s =190>s =110,故甲的波动比乙大,所以(2)的说法是正确的;从中位数上看,甲班学生跳绳次数有27人少于149次,27人大于149次,而乙班学生跳绳次数151次的必有27人,故必有至少28人跳绳次数高于150次,因而甲班学生成绩的优秀人数比乙班少,从而知(3)是正确的。 =110,故甲的波动比乙大,所以(2)的说法是正确的;从中位数上看,甲班学生跳绳次数有27人少于149次,27人大于149次,而乙班学生跳绳次数151次的必有27人,故必有至少28人跳绳次数高于150次,因而甲班学生成绩的优秀人数比乙班少,从而知(3)是正确的。 |
据专家权威分析,试题“在某次体育活动中,统计甲、乙两班学生每分钟跳绳的成绩(单位:次..”主要考查你对 平均数,中位数和众数,方差 等考点的理解。关于这些考点的“档案”如下:
平均数中位数和众数方差
考点名称:平均数
- 平均数:
是指在一组数据中所有数据之和再除以数据的个数。平均数是表示一组数据集中趋势的量数,它是反映数据集中趋势的一项指标。
解答平均数应用题的关键在于确定“总数量”以及和总数量对应的总份数。
在统计工作中,平均数(均值)和标准差是描述数据资料集中趋势和离散程度的两个最重要的测度值。 - 平均数的分类:
(1)算术平均数:一般地,如果有n个数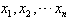 ,那么
,那么  ,叫做这n个数的算术平均数。
,叫做这n个数的算术平均数。
(2)加权平均数:一组数据 点的权分别为
点的权分别为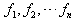 ,那么称
,那么称 为这n个数的加权平均数。
为这n个数的加权平均数。
(3)样本平均数:样本中所有个体的平均数。
(4)总体平均数:总体中所有个体的平均数,统计学中常用样本的平均数估计总体的平均数。 平均数、中位数和众数关系:
联系:
平均数、中位数和众数都是来刻画数据平均水平的统计量,它们各有特点。对于平均数大家比较熟悉,中位数刻画了一组数据的中等水平,众数刻画了一组数据中出现次数最多的情况。
平均数非常明显的优点之一是,它能够利用所有数据的特征,而且比较好算。另外,在数学上,平均数是使误差平方和达到最小的统计量,也就是说利用平均数代表数据,可以使二次损失最小。因此,平均数在数学中是一个常用的统计量。但是平均数也有不足之处,正是因为它利用了所有数据的信息,平均数容易受极端数据的影响。
例如,在一个单位里,如果经理和副经理工资特别高,就会使得这个单位所有成员工资的平均水平也表现得很高,但事实上,除去经理和副经理之外,剩余所有人的平均工资并不是很高。这时,中位数和众数可能是刻画这个单位所有人员工资平均水平更合理的统计量。
中位数和众数这两个统计量的特点都是能够避免极端数据,但缺点是没有完全利用数据所反映出来的信息。
由于各个统计量有各自的特征,所以需要我们根据实际问题来选择合适的统计量。
当然,出现极端数据不一定用中位数,一般,统计上有一个方法,就要认为这个数据不是来源于这个总体的,因而把这个数据去掉。比如大家熟悉的跳水比赛评分,为什么要去掉一个最高分、一个最低分呢,就认为这两个分不是来源于这个总体,不能代表裁判的鉴赏力。于是去掉以后再求剩下数据的平均数。需要指出的是,我们处理的数据,大部分是对称的数据,数据符合或者近似符合正态分布。这时候,均值(平均数)、中位数和众数是一样的。区别:
只有在数据分布偏态(不对称)的情况下,才会出现均值、中位数和众数的区别。所以说,如果是正态的话,用哪个统计量都行。如果偏态的情况特别严重的话,可以用中位数。
除了需要刻画平均水平的统计量,统计中还有刻画数据波动情况的统计量。比如,平均数同样是5,它所代表的数据可能是1、3、5、7、9,可能是4、4.5、5、5.5、6。也就是说5所代表的不同组数据的波动情况是不一样的。怎样刻画数据的波动情况呢?很自然的想法就是用最大值减最小值,即求一组数据的极差。数学中还有方差、标准差等许多用来刻画数据特征的统计量。当然这些都是教师感兴趣、值得了解的内容,不是小学数学的教学要求。- 平均数的求法:
(1)公式法: ;
;
(2)加权平均数公式: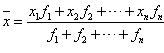 。
。
考点名称:中位数和众数
- 中位数:一般地,n个数据按大小顺序排列,处于最中间位置的一个数据(或最中间位置的两个数据的平均数)叫这组数据的中位数。
众数:在一组数据中,出现次数最多的数据。 - 中位数的位置:
当样本数为奇数时,中位数=(N+1)/2;当样本数为偶数时,中位数为N/2与1+N/2的均值
众数性质:
用众数代表一组数据,可靠性较差,不过,众数不受极端数据的影响,并且求法简便。在一组数据中,如果个别数据有很大的变动,选择中位数表示这组数据的“集中趋势”就比较适合。
当数值或被观察者没有明显次序(常发生于非数值性资料)时特别有用,由于可能无法良好定义算术平均数和中位数。例子:{鸡、鸭、鱼、鱼、鸡、鱼}的众数是鱼。
众数算出来是销售最常用的,代表最多的
众数是在一组数据中,出现次数最多的数据
两组数据中,都是1,2出现次数最多
所以1,2是众数
众数:
一般来说,一组数据中,出现次数最多的数就叫这组数据的众数。
例如:1,2,3,3,4的众数是3。
但是,如果有两个或两个以上个数出现次数都是最多的,那么这几个数都是这组数据的众数。
例如:1,2,2,3,3,4的众数是2和3。
还有,如果所有数据出现的次数都一样,那么这组数据没有众数。
例如:1,2,3,4,5没有众数。
在高斯分布中,众数位于峰值。
平均数、中位数和众数的特征:
(1)平均数、中位数、众数都是表示一组数据“平均水平”的平均数。
(2)平均数能充分利用数据提供的信息,在生活中较为常用,但它容易受极端数字的影响,且计算较繁。
(3)中位数的优点是计算简单,受极端数字影响较小,但不能充分利用所有数字的信息。 中位数算出来可避免极端数据,代表着数据总体的中等情况。
(4)众数的可靠性较差,它不受极端数据的影响,求法简便,当一组数据中个别数据变动较大时,适宜选择众数来表示这组数据的“集中趋势”。 平均数、中位数和众数异同:
一、相同点
平均数、中位数和众数这三个统计量的相同之处主要表现在:都是来描述数据集中趋势的统计量;都可用来反映数据的一般水平;都可用来作为一组数据的代表。
二、不同点
它们之间的区别,主要表现在以下方面。
1、定义不同
平均数:一组数据的总和除以这组数据个数所得到的商叫这组数据的平均数。
中位数:将一组数据按大小顺序排列,处在最中间位置的一个数叫做这组数据的中位数 。
众数:在一组数据中出现次数最多的数叫做这组数据的众数。
2、求法不同
平均数:用所有数据相加的总和除以数据的个数,需要计算才得求出。
中位数:将数据按照从小到大或从大到小的顺序排列,如果数据个数是奇数,则处于最中间位置的数就是这组数据的中位数;如果数据的个数是偶数,则中间两个数据的平均数是这组数据的中位数。它的求出不需或只需简单的计算。
众数:一组数据中出现次数最多的那个数,不必计算就可求出。
3、个数不同
在一组数据中,平均数和中位数都具有惟一性,但众数有时不具有惟一性。在一组数据中,可能不止一个众数,也可能没有众数。
4、呈现不同
平均数:是一个“虚拟”的数,是通过计算得到的,它不是数据中的原始数据。
中位数:是一个不完全“虚拟”的数。当一组数据有奇数个时,它就是该组数据排序后最中间的那个数据,是这组数据中真实存在的一个数据;但在数据个数为偶数的情况下,中位数是最中间两个数据的平均数,它不一定与这组数据中的某个数据相等,此时的中位数就是一个虚拟的数。
众 数:是一组数据中的原数据 ,它是真实存在的。
5、代表不同
平均数:反映了一组数据的平均大小,常用来一代表数据的总体 “平均水平”。
中位数:像一条分界线,将数据分成前半部分和后半部分,因此用来代表一组数据的“中等水平”。
众数:反映了出现次数最多的数据,用来代表一组数据的“多数水平”。
这三个统计量虽反映有所不同,但都可表示数据的集中趋势,都可作为数据一般水平的代表。
6、特点不同
平均数:与每一个数据都有关,其中任何数据的变动都会相应引起平均数的变动。主要缺点是易受极端值的影响,这里的极端值是指偏大或偏小数,当出现偏大数时,平均数将会被抬高,当出现偏小数时,平均数会降低。
中位数:与数据的排列位置有关,某些数据的变动对它没有影响;它是一组数据中间位置上的代表值,不受数据极端值的影响。
众数:与数据出现的次数有关,着眼于对各数据出现的频率的考察,其大小只与这组数据中的部分数据有关,不受极端值的影响,其缺点是具有不惟一性,一组数据中可能会有一个众数,也可能会有多个或没有 。
7、作用不同
平均数:是统计中最常用的数据代表值,比较可靠和稳定,因为它与每一个数据都有关,反映出来的信息最充分。平均数既可以描述一组数据本身的整体平均情况,也可以用来作为不同组数据比较的一个标准。因此,它在生活中应用最广泛,比如我们经常所说的平均成绩、平均身高、平均体重等。
中位数:作为一组数据的代表,可靠性比较差,因为它只利用了部分数据。但当一组数据的个别数据偏大或偏小时,用中位数来描述该组数据的集中趋势就比较合适。
众数:作为一组数据的代表,可靠性也比较差,因为它也只利用了部分数据。。在一组数据中,如果个别数据有很大的变动,且某个数据出现的次数最多,此时用该数据(即众数)表示这组数据的“集中趋势”就比较适合。- 中位数、众数的求法:
中位数:
①将数据按大小顺序排列;
②当数据个数为奇数时,中间的那个数据就是中位数;
当数据个数为偶数时,居于中间的两个数据的平均数才是中位数。
众数:找出频数最多的数据,若几个数据频数最多且相同,此时众数就是这几个数据。
考点名称:方差
- 方差:
是各个数据与平均数之差的平方和的平均数。
在概率论和数理统计中,方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。
在许多实际问题中,研究随机变量和均值之间的偏离程度有着很重要的意义。
设有n个数据各数据x1,x2,…,xn各数据与它们的平均数的差的平方分别是 ,
, ,…,
,…, ,我们用它的平均数,即用
,我们用它的平均数,即用 来衡量这组数据的波动大小,并把它叫做这组数据的方差,记作
来衡量这组数据的波动大小,并把它叫做这组数据的方差,记作 。
。 - 方差特点:
(1)设c是常数,则D(c)=0。
(2)设X是随机变量,c是常数,则有D(cX)=(c2)D(X)。
(3)设 X 与 Y 是两个随机变量,则
D(X+Y)= D(X)+D(Y)+2E{[X-E(X)][Y-E(Y)]}
特别的,当X,Y是两个相互独立的随机变量,上式中右边第三项为0(常见协方差),
则D(X+Y)=D(X)+D(Y)。此性质可以推广到有限多个相互独立的随机变量之和的情况。
(4)D(X)=0的充分必要条件是X以概率为1取常数值c,即P{X=c}=1,其中E(X)=c。
(5)D(aX+bY)=a^2DX+b^2DY+2abE{[X-E(X)][Y-E(Y)]}。
意义:
在样本容量相同的情况下,方差越大,说明数据的波动越大,越不稳定。
标准差:
方差的算术平均根,即 ,并把它叫做这组数据的标准差,它也是一个用来衡量一组数据的波动大小的重要的量。
,并把它叫做这组数据的标准差,它也是一个用来衡量一组数据的波动大小的重要的量。 公式:
方差是实际值与期望值之差平方的期望值,而标准差是方差算术平方根。 在实际计算中,我们用以下公式计算方差。
方差是各个数据与平均数之差的平方的平均数,即s^2=(1/n)[(x1-x_)^2+(x2-x_)^2+...+(xn-x_)^2],其中,x_表示样本的平均数,n表示样本的数量,^,xn表示个体,而s^2就表示方差。
而当用(1/n)[(x1-x_)^2+(x2-x_)^2+...+(xn-x_)^2]作为样本X的方差的估计时,发现其数学期望并不是X的方差,而是X方差的(n-1)/n倍,[1/(n-1)][(x1-x_)^2+(x2-x_)^2+...+(xn-x_)^2]的数学期望才是X的方差,用它作为X的方差的估计具有“无偏性”,所以我们总是用[1/(n-1)]∑(xi-X~)^2来估计X的方差,并且把它叫做“样本方差”。
方差,通俗点讲,就是和中心偏离的程度!用来衡量一批数据的波动大小(即这批数据偏离平均数的大小)并把它叫做这组数据的方差。记作S².在样本容量相同的情况下,方差越大,说明数据的波动越大,越不稳定。
方差分析主要用途:
①均数差别的显著性检验;
②分离各有关因素并估计其对总变异的作用;
③分析因素间的交互作用;
④方差齐性检验。
- 最新内容
- 相关内容
- 网友推荐
- 图文推荐
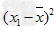
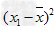
![已知一个样本的方差s2=1n[(x1-30)2+(x2-30)2+…+(xn-30)2],其平均数为______.-数学](http://www.00-edu.com/d/file/ks/shuxue/2/92/2019-04-14/d7ac5664148b8213cf2cc61f864868f2.png)

| [家长教育] 孩子为什么会和父母感情疏离? (2019-07-14) |
| [教师分享] 给远方姐姐的一封信 (2018-11-07) |
| [教师分享] 伸缩门 (2018-11-07) |
| [教师分享] 回家乡 (2018-11-07) |
| [教师分享] 是风味也是人间 (2018-11-07) |
| [教师分享] 一句格言的启示 (2018-11-07) |
| [教师分享] 无规矩不成方圆 (2018-11-07) |
| [教师分享] 第十届全国教育名家论坛有感(二) (2018-11-07) |
| [教师分享] 贪玩的小狗 (2018-11-07) |
| [教师分享] 未命名文章 (2018-11-07) |
