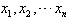芜湖市1985年~2008年各年度专利数一览表年度专利数年度专利数年度专利数年度专利数198501991211997562003138198621992271998552004165198731993321999110200518419888199422-数学
题文
芜湖市1985年~2008年各年度专利数一览表
(2)请用折线图描述2001年~2008年各年度的专利数; (3)请你根据这组数据,说出你得到的信息.  |
题文
芜湖市1985年~2008年各年度专利数一览表
(2)请用折线图描述2001年~2008年各年度的专利数; (3)请你根据这组数据,说出你得到的信息. |
答案
(1)中位数为46,极差为1006; (2)如图:  (3)芜湖的专利数从无到有,近几年专利数增加迅速.(必须围绕专利数据来谈) |
据专家权威分析,试题“芜湖市1985年~2008年各年度专利数一览表年度专利数年度专利数年度..”主要考查你对 中位数和众数,极差,折线图 等考点的理解。关于这些考点的“档案”如下:
中位数和众数极差折线图
考点名称:中位数和众数
平均数、中位数和众数异同:
一、相同点
平均数、中位数和众数这三个统计量的相同之处主要表现在:都是来描述数据集中趋势的统计量;都可用来反映数据的一般水平;都可用来作为一组数据的代表。
二、不同点
它们之间的区别,主要表现在以下方面。
1、定义不同
平均数:一组数据的总和除以这组数据个数所得到的商叫这组数据的平均数。
中位数:将一组数据按大小顺序排列,处在最中间位置的一个数叫做这组数据的中位数 。
众数:在一组数据中出现次数最多的数叫做这组数据的众数。
2、求法不同
平均数:用所有数据相加的总和除以数据的个数,需要计算才得求出。
中位数:将数据按照从小到大或从大到小的顺序排列,如果数据个数是奇数,则处于最中间位置的数就是这组数据的中位数;如果数据的个数是偶数,则中间两个数据的平均数是这组数据的中位数。它的求出不需或只需简单的计算。
众数:一组数据中出现次数最多的那个数,不必计算就可求出。
3、个数不同
在一组数据中,平均数和中位数都具有惟一性,但众数有时不具有惟一性。在一组数据中,可能不止一个众数,也可能没有众数。
4、呈现不同
平均数:是一个“虚拟”的数,是通过计算得到的,它不是数据中的原始数据。
中位数:是一个不完全“虚拟”的数。当一组数据有奇数个时,它就是该组数据排序后最中间的那个数据,是这组数据中真实存在的一个数据;但在数据个数为偶数的情况下,中位数是最中间两个数据的平均数,它不一定与这组数据中的某个数据相等,此时的中位数就是一个虚拟的数。
众 数:是一组数据中的原数据 ,它是真实存在的。
5、代表不同
平均数:反映了一组数据的平均大小,常用来一代表数据的总体 “平均水平”。
中位数:像一条分界线,将数据分成前半部分和后半部分,因此用来代表一组数据的“中等水平”。
众数:反映了出现次数最多的数据,用来代表一组数据的“多数水平”。
这三个统计量虽反映有所不同,但都可表示数据的集中趋势,都可作为数据一般水平的代表。
6、特点不同
平均数:与每一个数据都有关,其中任何数据的变动都会相应引起平均数的变动。主要缺点是易受极端值的影响,这里的极端值是指偏大或偏小数,当出现偏大数时,平均数将会被抬高,当出现偏小数时,平均数会降低。
中位数:与数据的排列位置有关,某些数据的变动对它没有影响;它是一组数据中间位置上的代表值,不受数据极端值的影响。
众数:与数据出现的次数有关,着眼于对各数据出现的频率的考察,其大小只与这组数据中的部分数据有关,不受极端值的影响,其缺点是具有不惟一性,一组数据中可能会有一个众数,也可能会有多个或没有 。
7、作用不同
平均数:是统计中最常用的数据代表值,比较可靠和稳定,因为它与每一个数据都有关,反映出来的信息最充分。平均数既可以描述一组数据本身的整体平均情况,也可以用来作为不同组数据比较的一个标准。因此,它在生活中应用最广泛,比如我们经常所说的平均成绩、平均身高、平均体重等。
中位数:作为一组数据的代表,可靠性比较差,因为它只利用了部分数据。但当一组数据的个别数据偏大或偏小时,用中位数来描述该组数据的集中趋势就比较合适。
众数:作为一组数据的代表,可靠性也比较差,因为它也只利用了部分数据。。在一组数据中,如果个别数据有很大的变动,且某个数据出现的次数最多,此时用该数据(即众数)表示这组数据的“集中趋势”就比较适合。
考点名称:极差
极差:
全距,又称极差,是用来表示统计资料中的变异量数,其最大值与最小值之间的差距;
即最大值减最小值后所得之数据。
极差是指总体各单位的标志值中,最大标志值与最小标志值之差。它是标志值变动的最大范围。极差也称为全距或范围误差,它是测定标志变动的最简单的指标。换句话说,也就是指一组数据中的最大数据与最小数据的差叫做这组数据的极差。 极差英文为range ,简写为R,表示为:R=Xmax-Xmin。移动极差(Moving Range)是其中的一种。
极差特点:
刻画数据离散程度的最简单的统计量;
计算简单;
不能反映中间数据的分散状况。
极差用途:
在统计中常用极差来刻画一组数据的离散程度,以及反映的是变量分布的变异范围和离散幅度,在总体中任何两个单位的标准值之差都不能超过极差。同时,它能体现一组数据波动的范围。极差越大,离散程度越大,反之,离散程度越小。
极差只指明了测定值的最大离散范围,而未能利用全部测量值的信息,不能细致地反映测量值彼此相符合的程度,极差是总体标准偏差的有偏估计值,当乘以校正系数之后,可以作为总体标准偏差的无偏估计值,它的优点是计算简单,含义直观,运用方便,故在数据统计处理中仍有着相当广泛的应用。 但是,它仅仅取决于两个极端值的水平,不能反映其间的变量分布情况,同时易受极端值的影响。
考点名称:折线图
| [家长教育] 孩子为什么会和父母感情疏离? (2019-07-14) |
| [教师分享] 给远方姐姐的一封信 (2018-11-07) |
| [教师分享] 伸缩门 (2018-11-07) |
| [教师分享] 回家乡 (2018-11-07) |
| [教师分享] 是风味也是人间 (2018-11-07) |
| [教师分享] 一句格言的启示 (2018-11-07) |
| [教师分享] 无规矩不成方圆 (2018-11-07) |
| [教师分享] 第十届全国教育名家论坛有感(二) (2018-11-07) |
| [教师分享] 贪玩的小狗 (2018-11-07) |
| [教师分享] 未命名文章 (2018-11-07) |
![某班甲、乙两组模拟考成绩的盒状图如图所示.若甲、乙两组模拟考成绩的极差分别为a、b;中位数分别为c、d,则a、b、c、d的大小关系,下列何者正确?[]A.a<b且c>dB.a&l-九年级数学](http://www.00-edu.com/d/file/ks/shuxue/2/93/2019-04-14/1763e86cc602affc40dfc9e351d9321a.png)
![在一次中学生田径运动会上,参加男子跳高的15名运动员的成绩如下表:这些运动员跳高成绩的中位数和众数分别是[]A.1.65,1.70B.1.70,1.65C.1.70,1.70D.3,5-九年级数学](http://www.00-edu.com/d/file/ks/shuxue/2/93/2019-04-14/c325d134726e734a0c45ba6bbc3c3878.gif)
![为了了解某校2009年初三学生体育测试成绩,从中随机抽取了50名学生的体育测试成绩如下表:则这50名学生的体育测试成绩的众数、中位数分别为[]A.24,24B.8,24C.24,23.5D-九年级数学](http://www.00-edu.com/d/file/ks/shuxue/2/93/2019-04-14/7e67304eabdffa90f75b3e96c4119112.gif)
![某电脑公司试销同一价位的品牌电脑,一周内销售情况如下表所示:要了解哪种品牌最畅销,公司经理最关心的是上述数据找[]A.平均数B.众数C.中位数D.方差-九年级数学](http://www.00-edu.com/d/file/ks/shuxue/2/93/2019-04-14/af758fef114f1a7fa00ccb52dc0427e4.gif)