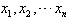国际奥委会2003年6月29日决定,2008年北京奥运会的举办日期由7月25日至8月10日推迟至8月8日至24日,原因与北京地区的气温有关,为了了解这段时间北京的气温分布状况,相关部-数学
题文
国际奥委会2003年6月29日决定,2008年北京奥运会的举办日期由7月25日至8月10日推迟至8月8日至24日,原因与北京地区的气温有关,为了了解这段时间北京的气温分布状况,相关部门对往年7月25日至8月24日的日最高气温进行抽样,得到如下样本数据:
(2)若日最高气温33℃(含33℃)以上为高温天气,根据以上数据预测北京2008年7月25日至8月10日和8月8日至24日期间分别出现高温天气的概率是多少; (3)根据(1)和(2)得到的数据,对北京奥运会的举办日期因气温原因由7月25日至8月10日推迟至8月8日至24日做出解释. | ||||||||||||||||||||||||||||||||||||||||||||||||
 会稳定在某个常数p附近,那么这个常数p就叫做事件A的概率,记作P(A)=p,概率从某种数量上刻画一个不确定事件发生的可能性的大小。
会稳定在某个常数p附近,那么这个常数p就叫做事件A的概率,记作P(A)=p,概率从某种数量上刻画一个不确定事件发生的可能性的大小。 ≤1,故0≤P(A)≤1;
≤1,故0≤P(A)≤1;![某班甲、乙两组模拟考成绩的盒状图如图所示.若甲、乙两组模拟考成绩的极差分别为a、b;中位数分别为c、d,则a、b、c、d的大小关系,下列何者正确?[]A.a<b且c>dB.a&l-九年级数学](http://www.00-edu.com/d/file/ks/shuxue/2/93/2019-04-14/1763e86cc602affc40dfc9e351d9321a.png)
![在一次中学生田径运动会上,参加男子跳高的15名运动员的成绩如下表:这些运动员跳高成绩的中位数和众数分别是[]A.1.65,1.70B.1.70,1.65C.1.70,1.70D.3,5-九年级数学](http://www.00-edu.com/d/file/ks/shuxue/2/93/2019-04-14/c325d134726e734a0c45ba6bbc3c3878.gif)
![为了了解某校2009年初三学生体育测试成绩,从中随机抽取了50名学生的体育测试成绩如下表:则这50名学生的体育测试成绩的众数、中位数分别为[]A.24,24B.8,24C.24,23.5D-九年级数学](http://www.00-edu.com/d/file/ks/shuxue/2/93/2019-04-14/7e67304eabdffa90f75b3e96c4119112.gif)
![某电脑公司试销同一价位的品牌电脑,一周内销售情况如下表所示:要了解哪种品牌最畅销,公司经理最关心的是上述数据找[]A.平均数B.众数C.中位数D.方差-九年级数学](http://www.00-edu.com/d/file/ks/shuxue/2/93/2019-04-14/af758fef114f1a7fa00ccb52dc0427e4.gif)